随着高通量技术的发展,通过世界各地研究人员的共同努力,形成了大型公共数据库,如癌症基因组图谱(TCGA)。这对阐明疾病表型的分子机制具有重大意义。然而,由于癌症等复杂疾病的病理以及其在遗传、基因组和蛋白质组水平上复杂的分子机制,研究复杂的人类疾病仍具有挑战性。目前,已有很多基于机器学习的方法开发出来,包括非线性核支持向量机(SVMs)、随机森林(RFs)和人工智能领域的深度神经网络(DNNs),为药物反应和医学影像分类等临床相关的生物医学和生物组学数据建立了更强大的预测模型。然而这些模型算法较为复杂,存在信息不透明性,且难以解释每个单独特征的作用。然而,识别重要的生物标志物可以协助研究人员建立关于预防、诊断和治疗复杂人类疾病的新假设。
再生医学网了解到一项最新研究,在本研究中,研究人员提出了一种基于排列的特征重要性测试(PermFIT),用于估计和测试特征的重要性。PermFIT(https://github.com/SkadiEye/deepTL)采用计算效率高的方式实现,无需模型改装。PermFIT可解释复杂框架中的单个特征,包括深度神经网络,随机森林和支持向量机。
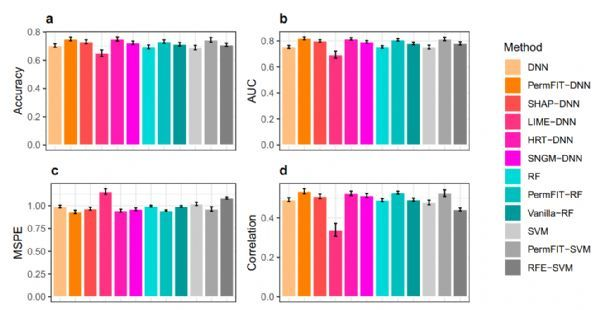
通过对TCGA肾癌数据和HITChip Atlas体重数据的应用展示,PermFIT程序进一步显示了其优越性能。通过PermFIT程序的特征选择显着提高了这些预测模型的性能。然而,值得指出的是,PermFIT的预测性能改善受限于每个机器学习模型框架的能力。例如,RF在建模交互项方面相对低效,因此PermFIT-RF的性能可能会受到具有基因-基因强交互作用的复杂性状的限制。总体上,PermFIT与DNN的结合始终显示了优越性能。
总之,研究人员通过在不同场景下进行的大量数据研究表明,PermFIT不仅能得到有效的统计推断,还能提高机器学习模型的预测精度。PermFIT在肾癌基因图谱数据和HITChip图谱数据的应用,展示了其在识别重要生物标志物和提高模型预测性能方面的实际应用性能。
(备注:图片源自网络。)